5. Segmentation (세그먼테이션)
segment란? / segmentation이란?
프로그램의 의미(기능) 단위 / 프로그램을 세그먼트로 나누어 물리적 메모리에 올리는 기법
하나의 프로세스를 구성하는 주소 공간은 일반적으로 코드, 데이터, 스택 등의 의미있는 단위들로 구성된다. 세그먼트는 이와 같이 주소 공간을 기능 단위 또는 의미 단위로 나눈 것을 뜻한다. 프로세스의 주소 공간 전체를 하나의 세그먼트로 볼 수도 있으며, 일반적으로는 코드, 데이터, 스택 등의 기능 단위로 세그먼트를 정의한다. 작게는 프로그램을 구성하는 함수 하나하나를 세그먼트로 정의할 수도 있다.
세그먼트는 의미 단위로 잘랐기 때문에 크기가 균열하지 않다. 크기가 균열하지 않은 세그먼트들을 메모리에 적재하는 부가적인 오버헤드가 따른다.
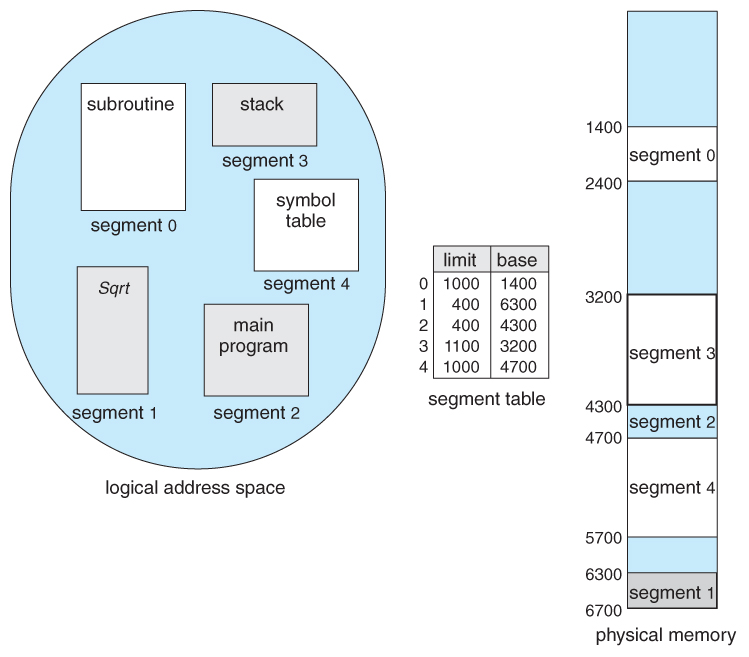
<Segmentation Architecture>
logical address는 다음의 두 가지로 구성된다. <Segment-number, offset>
세그먼트 번호는 해당 논리적 주소가 프로세스 주소 공간 내에서 몇 번째 세그먼트에 속하는지를 나타낸다
오프셋은 그 세그먼트 내에서 얼마만큼 떨어져 있는지에 대한 정보를 나타낸다.
Segement Table
세그먼테이션 기법에서는 주소 변환을 위해 세그먼트 테이블을 사요한다. 세그먼트 테이블의 각 항목은 기준점(base)와 한계점(limit)을 가지고 있다. base는 starting phisical address of the segment: 물리적 메모리 시작점을 나타낸다. limit은 length of the segment: 세그먼트의 길이를 나타낸다. 페이징 기법에서는 모든 페이지의 길이가 동일하므로 페이지 테이블의 각 항목에 기준점이라고 할 수있는 페이지 프레임 위치만 유지하면 되지만, 세그먼테이션 기법에서는 세그먼트가 의미 단위로 자른, 길이가 균일하지 않으므로 세그먼트의 위치 정보 뿐 아니라 길이 정보까지 유지해야 하는 것이다.
페이징 기법에서 PTBR, PTLR가 있는 것 처럼 세그먼트도 레지스터의 도움을 받는다
Segment - table base register(STBR): 물리적 메모리에서의 segment table의 위치(시작 위치)
segment - table length register(STLR): 프로그램이 사용하는 segment의 수

논리적 주소에서 물리적 주소로 변환하기 전에 두 가지를 확인하는데 1. 요청된 세그먼트 번호가 STLR에 저장된 값보다 작은가? 2. 논리적 주소의 오프셋 값이 그 세그먼트의 길이보다 작은 값인가? 세그먼트 테이블의 해당 항목에 있는 한계점과 요청된 논리적 주소의 오프셋 값을 비교하여 확인한다.
<Segmentation Architecture>
Protection
세그먼트 테이블의 각 항목에 보호비트와 유효비트를 둔다. 보호 비트는 페이징 기법의 보호비트와 마찬가지로 읽기, 쓰기, 실행 등의 권한이 있는지? 유효 비트는 해당 세그먼트가 현재 물리적 메모리에 적재되어 있는지를 나타냄
<sharing>
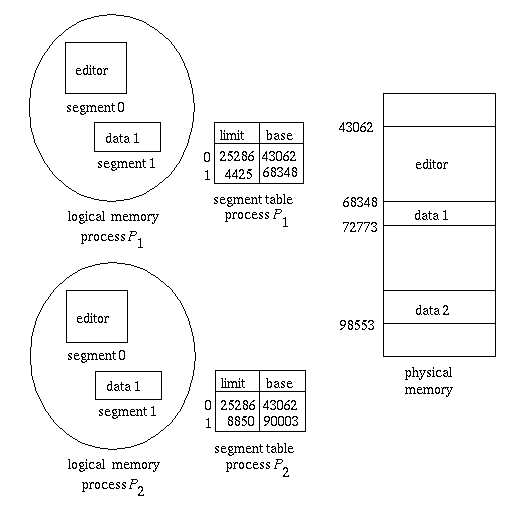
세그먼테이션 기법에서도 공유 세그먼테이션이 있는데 공유 세그먼트는 이 세그먼트를 공유하는 모든 프로세스의 주소 공간에서 동일한 논리적 주소에 올라가야 한다.
세그먼트는 의미 단위로 나뉘어져 있기에 공유와 보안의 측면에서 페이징에 비해 훨씬 효과적이다.
세그먼트는 외부조각이 발생하게 된다. 길이가 균등하지 않기 때문이다. 따라서 연속 할당 메모리의 가변분할 방식처럼 first fit, best fit 방식이 있다.
6. Paged Segmentation (페이지드 세그멘테이션)
프로그램을 의미 단위인 세그먼트로 나누는데 임의의 길이를 가질 수 있는게 아니라 반드시 동일한 크기 페이지들의 집합으로 구성되어야 하며, 물리적 메모리에 적재하는 단위는 페이지 단위로 한다. 즉 페이지드 세그먼테이션에서는 하나의 세그먼트 크기를 페이지 크기의 배수가 되도록 함으로써 세그먼테이션 기법에서 발생하는 외부 조각의 문제점을 해결하며 동시에 세그먼트 단위로 프로세스 간의 공유나 보안면에서 접근 권한 보호가 이루어지게 함으로 페이징 기법의 단점을 해소한다.

주소변환을 위해 외부의 세그먼트 테이블과 내부의 페이지 테이블로 이루어진 두 단계 테이블을 이용한다.
pure segmentation과의 차이점 segment table entry가 segment의 base address를 가지고 있는 것이 아니라 segment를 구성하는 page table의 base address를 가지고 있다. 하나의 세그먼트가 여러 개의 페이지로 구성되므로 각 세그먼트마다 페이지 테이블을 가지게 된다.
<세그먼트 번호, 오프셋>으로 구성된 논리적 주소를 물리적 주소로 변환하려면 논리적 주소의 상위 비트인 세그먼트 번호를 통해 세그먼트 테이블의 해당 항목에 접근한다. 이 세그먼트 항목에는 세그먼트 길이와 그 세그먼트의 페이지 테이블 시작 주소가 들어있다. 이 때 세그먼트 길이를 넘어서는 비정상적 접근 시도인지 여부를 체크하기 위해 먼저 세그먼트 길이값과, 논리적 주소 중 하위비트인 오프셋 값을 비교한다. 오프셋이 더 크다면 잘못된 접근 시도이므로 트랩을 발생시키고 그렇지 않다면 오프셋을 다시 상위 하위 비트로 나누어 상위 비트는 그 세그먼트 내에서 페이지 번호로 사용하고 하위 피트는 페이지 내에서의 변위로 나타낸다. 세그먼트 테이블의 항목을 통해 해당 세그먼트를 위한 페이지 테이블의 시작 위치를 얻었으므로 그 위치에서 페이지 번호만큼 떨어진 페이지 테이블 항목으로부터 물리적 메모리의 페이지 프레임 위치를 얻게 된다. 그 위치에서 오프셋의 하위 비트 값인 페이지 내 변위만큼 떨어진 곳이 원하는 곳의 물리적 메모리 주소가 된다.
'CS > operating system' 카테고리의 다른 글
| Virtual Memory: 가상 메모리 (2/2) (0) | 2021.02.22 |
|---|---|
| Virtual Memory: 가상 메모리 (1/2) (0) | 2021.02.19 |
| Memory Management: 메모리 관리 (2/3) (0) | 2021.02.17 |
| Memory Management: 메모리 관리 (1/3) (0) | 2021.02.16 |
| CPU Scheduling: CPU 스케줄링 (2/2) (0) | 2021.02.13 |