* Hash?
임의의 길이 데이터를 고정된 길이의 데이터로 매핑하는 함수이다.
특징:
- 뭘 넣든 비슷한 길이의 알 수 없는 난수가 결과로 출력된다.
- 글자가 한 글자만 바뀌어도 완전히 다른 결과가 출력된다.
- 출력값으로 임의의 값을 예측할 수 없다.
- 같은 내용을 입력 값으로 주면 결과값은 언제나 같다.
이를 이용해 해시 테이블이라는 자료구조를 사용할 수 있으며 해시 값 자체를 index로 사용한다. 따라서 시간 복잡도는 O(1)로 매우 빠른 데이터 검색이 가능하다.
* Hashing 과정
키(Key) ----> 해시 함수(hash function) ----> 해시값(hash value)
[이름] [해싱과정] [index(hash value) : data]
* 키(key) : 매핑 전 원래 데이터의 값
* 해시값: 매핑 후 데이터의 값
* Hash Table
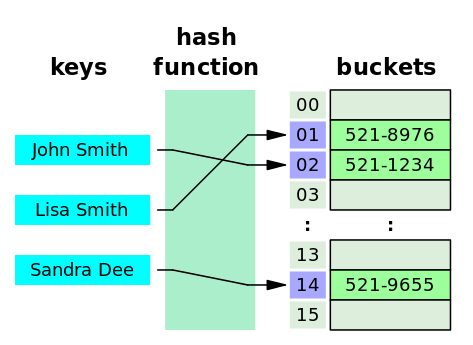
해시 함수를 사용하여 key를 해시 값으로 매핑하여 이를 index 또는 주소 삼아 데이터의 값(value)를 키와 함께 저장하는 자료구조이다. 해시 함수는 입력으로 key를 받아, 0부터 배열의 크기 -1사이의 값을 출력한다. -> index!
* Collision(충돌)
- Separate Chaining(개별 체이닝)

충돌 발생 시 연결 리스트로 연결하는 방식이다. 동일한 해쉬값이 출력되어 충돌이 발생하면, 그 위치에 있던 데이터에 key값을 포인터로 뒤이어 연결한다. 최악의 경우, 즉 모든 데이터의 해시값이 충돌하여 하나의 값으로 나왔을경우(모두 일치할 경우) 연결리스트의 탐색 시간과 동일한 선형 시간을 가지게 된다.
- Open Addressing(오픈 어드레싱)

충돌 발생 시 탐사를 통해 빈 공간을 찾아나서는 방식이다. 체이닝 방식은 링크드 리스트로 관리하기 때문에 무한정 데이터를 저장할 수 있으나, 오픈 어드레싱 방식은 전체 슬롯의 개수 이상은 저장할 수 없다. 또한 충돌이 발생하면 빈 공간을 찾아(Probing) 저장하기 때문에 모든 원소가 반드시 자신의 해시값과 일치하는 index에 저장된다는 보장은 없다. 그림에서 보면 윤아와 서현이가 충돌했기 때문에 충돌한 인덱스인 2 다음의 3부터 탐색했는데 비어있으니까 서현이가 3에 들어가는 방식.
충돌 해결을 해도 성능 저하는 필연적이며 수용률이 일정한 비율을 넘어서게 되면 성능이 모두 떨어지기 때문에 수용률이 일정량을 넘어서게 되면 리스트 자체의 크기를 키운 뒤 재배열을 하는 방법을 사용한다. 다만 재배열을 하는 과정 등에서 많은 비용이 소요되기 때문에 실시간으로 빠르게 처리를 해야 하는 환경에서는 무리가 있다.
'CS > algorithm' 카테고리의 다른 글
| 에라토스테네스의 체 (0) | 2021.07.19 |
|---|---|
| Divide and Conquer Algorithm (분할 정복 알고리즘) (0) | 2021.06.16 |
| Binary Search Algorithm (이진 탐색 알고리즘) (0) | 2021.06.14 |
| PRIM MST Algorithm (프림 알고리즘) (0) | 2021.05.16 |
| Kruskal MST Algorithm (크루스칼 알고리즘) (0) | 2021.05.15 |